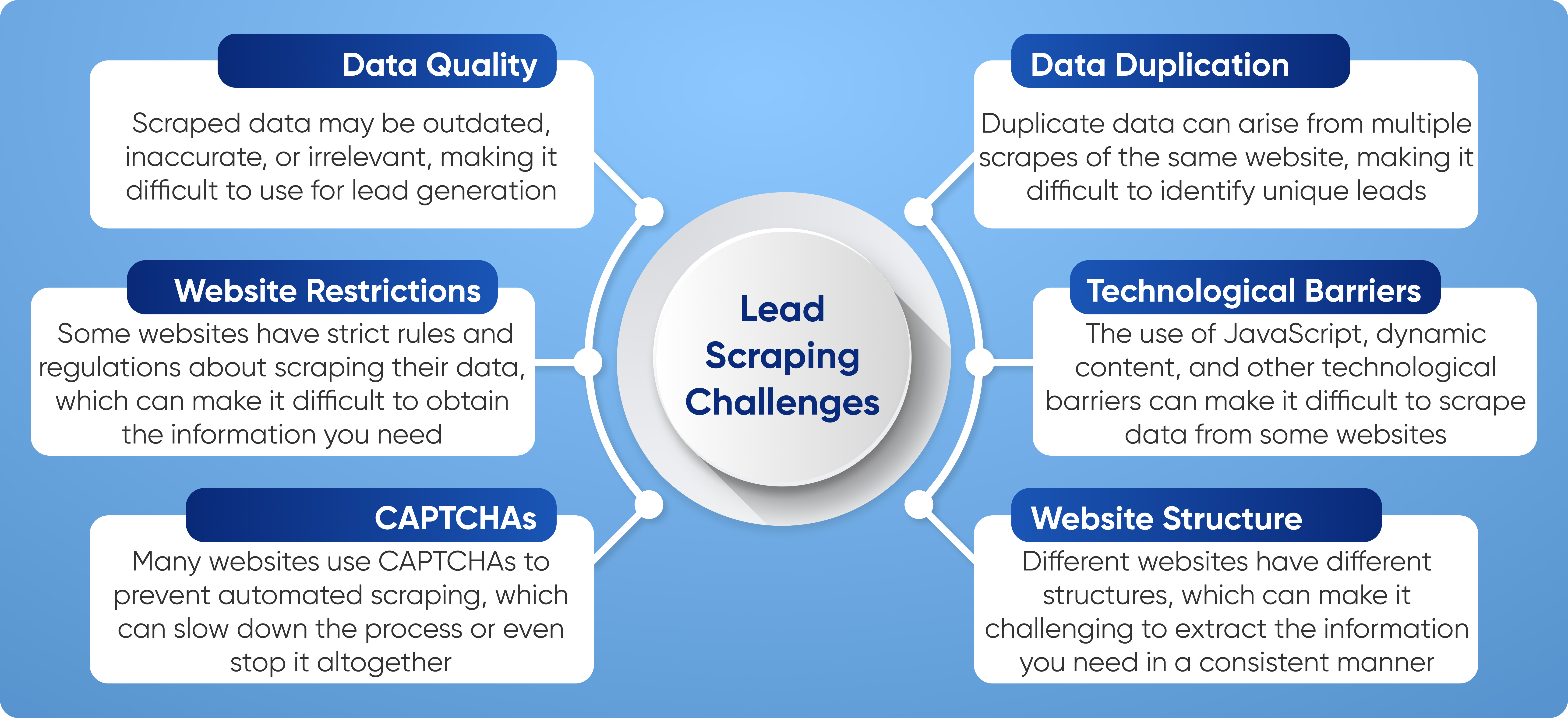
Web Scratching Vs Web Crawling: Whats The Difference? This might refer to essentially any type of kind of information from a range of various sources-- storage space tools, spread sheets, etc. The data does not need to be from the net or a website, as we are talking about data scuffing in a more comprehensive feeling, and not specifically web scratching. The web crawling done by these web crawlers and robots need to be done carefully with focus and correct care. The deepness of the infiltration have to not breach the restrictions of web sites or privacy regulations when they are creeping various sites. Any type of violation of such can lead to claims from whatever huge information domain name that might have been angered, and that is something that nobody desires knotted in. This way, you don't have to waste long hours that result in a poor job that consists of encountering legal difficulties. If done properly by individuals that know what they're doing, these programs will certainly give you the vital support you need to get ahead in your industry. Lots of people don't understand the distinction in between information scuffing and data creeping. This confusion results in misunderstandings over what solution a company needs. This procedure is needed for filtering system and distinguishing various kinds of raw data from various sources into something that is useful and helpful. Information scratching is much more details in what it removes than information crawling.
- Data creeping got its name from spiders who creep around the facilities.As for spiders, you may not necessarily need them-- however you'll take advantage of information creeping when you'll be googling some questions.This might be cost details from a specific website or searching for addresses from an on-line directory site.For some information extraction, a person will want scraping, for other types, creeping is required.
Information Access Outsourcing Enhances The Company's Earnings
Scrapes do not have to stress over being courteous or adhering to any moral regulations. Crawlers, though, need to see to it that they are respectful to the web servers. They have to operate in a way such that they do not anger the web servers, and have to be dexterous sufficient to extract all the details required. Generally, this information gets copied, and numerous web pages wind up having the exact same information. While the robots do not have any methods of recognizing this duplicate details, getting rid of the exact same information is necessary. For that reason, information de-duplication ends up being a part of web crawling.How SMBs Can Avoid Data Deluge in the Cloud - Spiceworks News and Insights
How SMBs Can Avoid Data Deluge in the Cloud.
Posted: Thu, 22 Jun 2023 07:00:00 GMT [source]